24Nov2025
-
24Nov2025
Beyond the Lab: Informed decision-making strategy for resampling in pain assessment
In many real-world classification problems, datasets exhibit a skewed class distribution, known as class imbalance, where one class has significantly more samples than another.
Machine learning models trained on imbalanced data tend to favor the class with more samples. This bias toward the majority class leads to poor classification performance on rare but important cases, such as detecting a disease.
One common solution is to perform oversampling, which generates new, synthetic samples for the minority class to rebalance the training data.
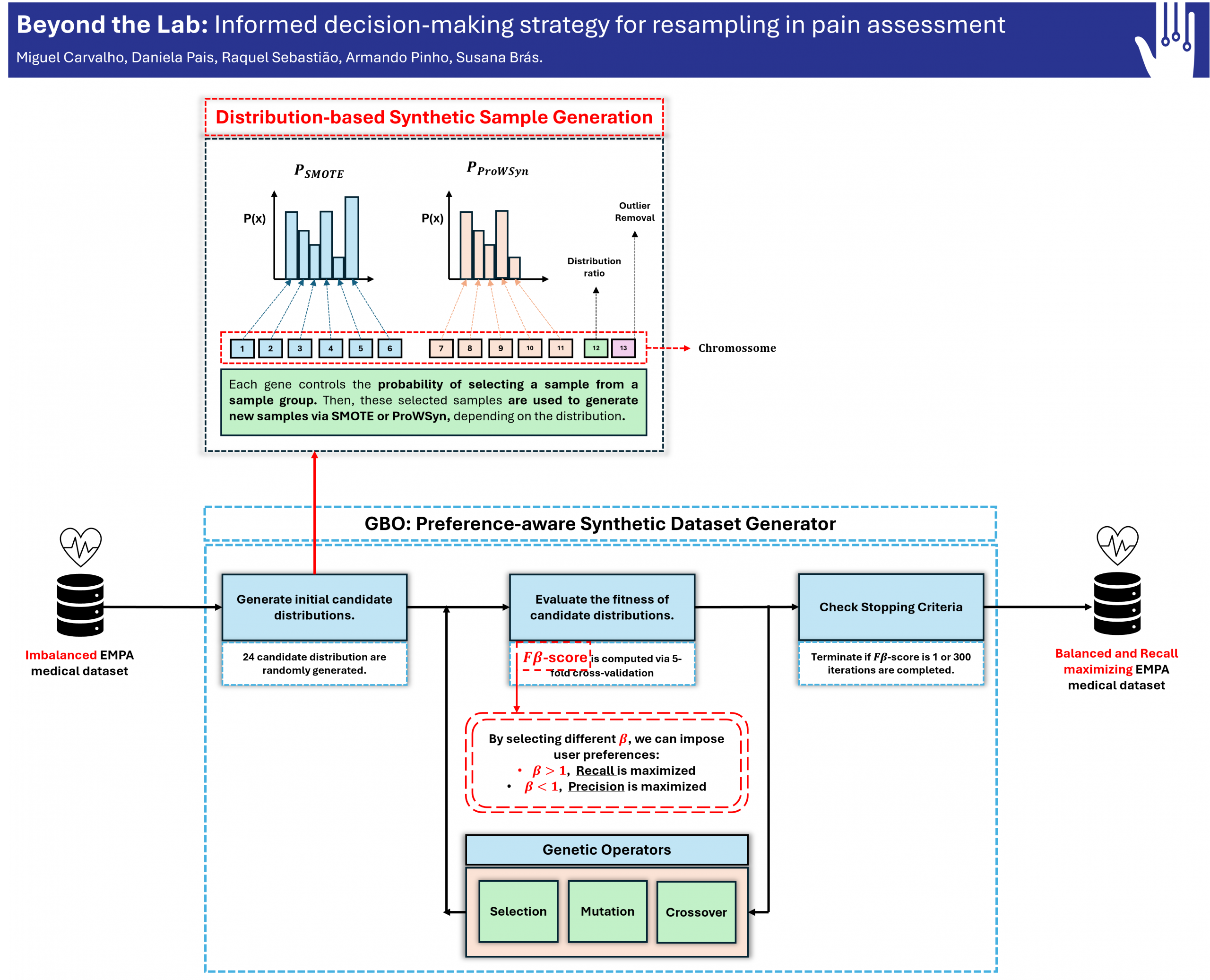
Proposed approach
This work proposes a novel resampling algorithm called Genetic Beta Oversampling (GBO) that incorporates user-defined preferences into the synthetic data generation process. GBO allows users to control whether the model should prioritize minimizing false negatives (e.g., reducing missed diagnoses of true disease cases) or minimizing false positives (e.g., reducing incorrect diagnoses of healthy patients).
Pain detection
In pain classification, failing to identify patients experiencing pain can result in unnecessary suffering and potential complications. GBO allows the resampling method to prioritize maximizing recall, reducing false negatives, and therefore improving the model’s ability to identify true cases of pain, supporting better patient care.
Authored by: Miguel Carvalho
In collaboration with: Daniela Pais, Raquel Sebastião, Armando Pinho, and Susana Brás
Supported by: This work was supported by national funds through FCT—Fundação para a Ciência e a Tecnologia, I.P., under PhD grants PRT/BD/154859/2023 (M.C) and UI/BD/153374/2022 (D.P.), and by the European Regional Development Fund, FSE through COMPETE2020. This work was also funded by FCT, through national funds, under unit 00127-IEETA.
Publication’s DOI: https://doi.org/10.1007/978-3-031-99568-2_12
Share in: